Machine Learning Systems Design
Note
Most of the notes are from the book Machine Learning Systems Design
Overview of Machine Learning Systems Design
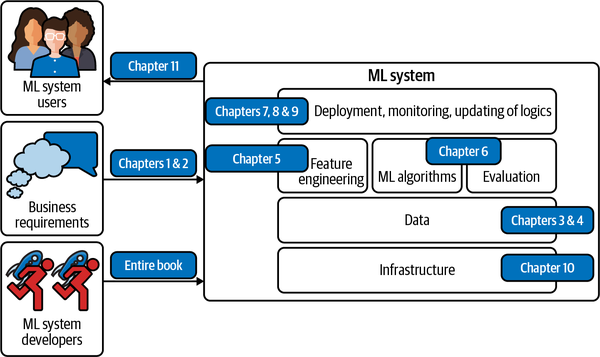
MLOps
What is MLOps (Machine Learning Operations)
- Ops in MLOps comes from DevOps, short for Developments and Operations.
- To operationalize something means to bring it into production, which includes deploying, monitoring, and maintaining it.
- MLOps is a set of tools and best practices for bringing ML into production.
Requirements for ML Systems
- Reliability
- Scalability
- resource scaling
- artifact management
- Maintainability
- **Adaptability **
- data distribution shifts
- Continual Learning: ML System Monitoring and Continual learning#Continual Learning
Iterative Process of Developing an ML system
1. Project scoping
2. Data engineering
Data pipeline in MLOps
Major types of data problems
- unstructured vs. structured
- unstructured: humans can label data; data augmentation is feasible
- structured: hard to obtain more data
- small vs. big data
- small data: clean and consistent labels are critical
- big data: data process are important
Data pipeline at difference phases
- POC (proof-of-concept)
- goal is to decide if the application is workable and worth deploying
- focus on getting the prototype to work
- acceptable if data pre-processing is manual - but take extensive notes/comments
- production phase
- after project utility is established, use more sophisticated tools to make sure the data pipeline is replicable
Best practice
- to keep track of:
- data provenance: where data comes from
- data lineage: sequence of steps applied to data
- use meta-data
3. ML model development
Coping with ML training challenges
Checkpointing
- check points include
- model architecture
- model weights
- training configurations
- optimizer
- take two things into consideration: frequency and number of checkpoints
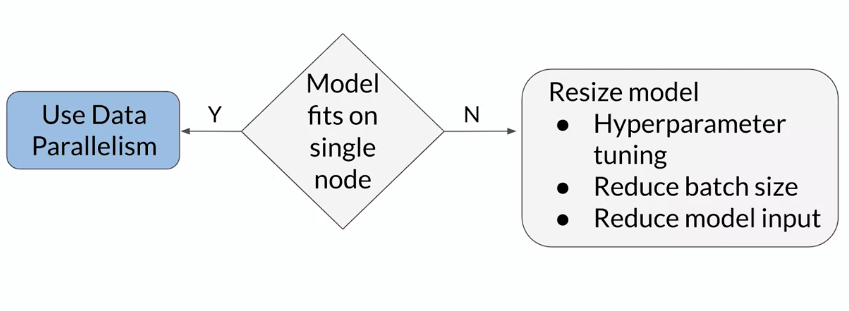
Distributed training strategies
-> scale challenges: increased training data volume or increased model size and complexity
- Distributed training = split training load across multiple compute nodes or clusters (CPU/GPU)
- there are two strategies
- data parallelism: training data split up + model replicated on all notes
- model parallelism: training data replicated + model split up on all nodes
- which to choose:
Best practice: Sanity-check test
- try to overfit a small training dataset before training on a large one
4. ML Model Deployment
5. ML System Monitoring and Continual learning
6. Business analysis
Infrastructure and Tooling for MLOps
Infrastructure
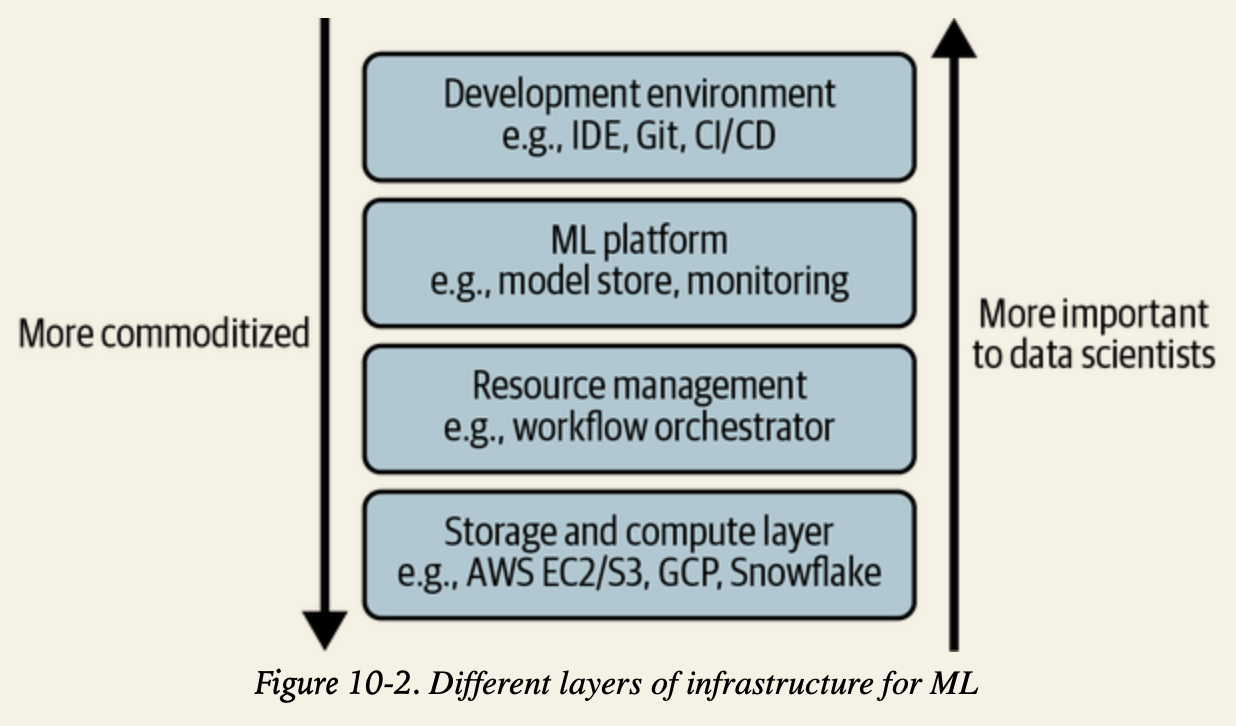
Storage & Compute
- storage layer: where data is collected and stored
- hard drive disk (HDD), solid state disk (SSD)
- AWS Storage & Databases#Amazon Simple Storage Service (Amazon S3), Snowflake
- compute layer: all the compute resources a company has access to and the mechanism to determine how these resources can be used
- CPU, GPU
- Amazon EC2, GCP
Development Environment
- IDE (Integrated development environment)
- cloud IDE: AWS Cloud9, Amaon SageMaker Studio
- versioning
- CI/CD
Resource Management
- Cron, Schedulers, Orchestrators
- cron: it run a script at a predetermined time and tell you whether the job succeeds or fails
- scheduler & orchestrator
- scheduler: cron programs deciding when
- orchestrator: cron programs concerning where to get resources. e.g. Kubernetes
- scheduler and orchestrator can be used interchangeably
- Data science workflow management
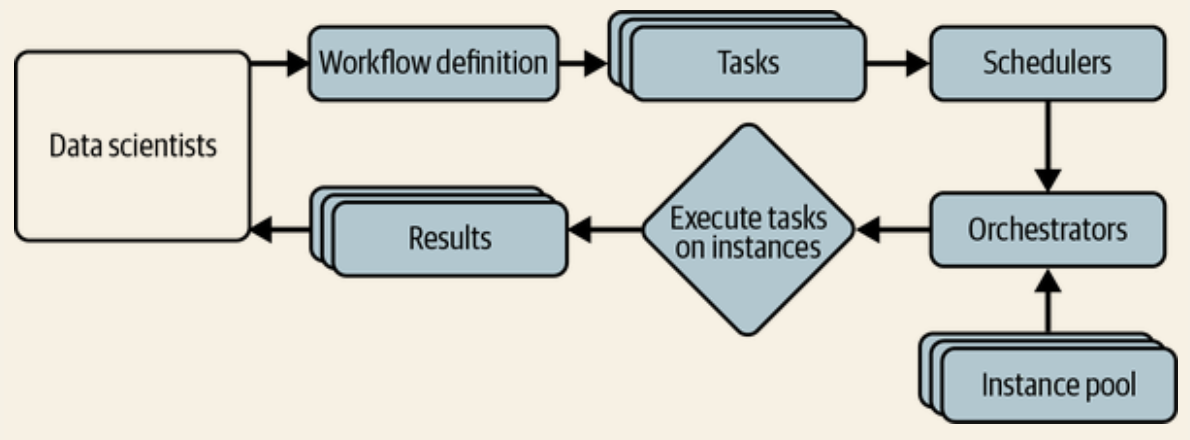
Pipeline Orchestration
orchestration allows managing end to end traceability of pipeline using automation to capture specific inputs, outputs, and artifacts of a given task.
-
Model lineage
- for each version of a trained model, versions of
- data used
- code/hyperparamters used
- algorithm/framework
- training docker image
- packages/libraries
- for each version of a trained model, versions of
-
Model registry
- centrally manage model metadata and model artifacts
- track which models are deployed across environments
-
Artifact tracking
- artifact = the output of a step or task can be consumed by the next step in a pipeline or deployed directly for consumption
Model Integration
= integrating models with ML applications
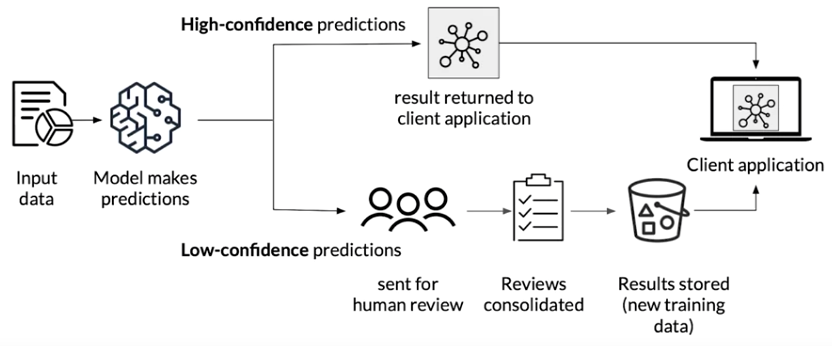
Human-in-the-Loop Pipelines
Human review of model predictions